
Билет 21
Оглавление
Кодирование текстовой информации.
Поскольку текст изначально дискретен — он состоит из отдельных символов, — для компьютерного представления текстовой информации используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — кодов символов, его составляющих. При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются так называемые кодовые таблицы символов, в которых каждому коду символа ставится в соответствие изображение символа.
Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов. На заре компьютерной эпохи, когда США были абсолютным лидером в этой области, стандарты разрабатывались Американским национальным институтом стандартизации (ANSI); впоследствии для разработки и принятия компьютерных стандартов была создана Международная организация стандартизации (ISO).
В программировании наиболее часто используются однобайтовые кодировки: в них код каждого символа занимает ровно 1 байт, или 8 бит. При этом общее количество различаемых символов составляет 28 = 256, а коды символов имеют значения от 0 до 255.
Информационным объемом блока информации называется количество бит, байт или производных единиц (килобайт, мегабайт и т. д.), необходимых для записи этого блока путем заранее оговоренного способа двоичного кодирования.
Задание. Оцените в байтах объем текстовой информации в современном словаре иностранных слов из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы).
Решение. Будем считать, что при записи используется кодировка «один символ — один байт». Количество символов во всем словаре равно 80* 60* 740 = 3 552 000. Следовательно, объем в байтах равен 3 552 000 байт = 3 468,75 Кбайт =3,39Мбайт.
Основой для компьютерных стандартов кодирования символов послужил АSCII — американский стандартный код для обмена информацией, разработанный в 1960-х годах и применяемый в США для любых видов передачи информации, в том числе и некомпьютерных (телеграф, факсимильная связь и т. д.). В нем используется 7-битовое кодирование: общее количество символов составляет 27 = 128, из них первые 32 символа — управляющие, а остальные — «изображаемые», т. е. имеющие графическое изображение. Управляющие символы должны восприниматься устройством вывода текста как команды, например:

К изображаемым символам в АSCII относятся буквы английского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Фрагмент кодировки АSCII приведен в табл. 1.
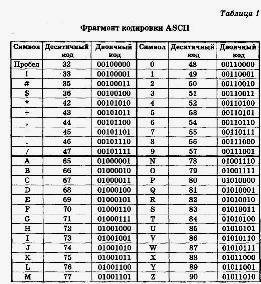
Хотя в АSCII символы кодируются 7 битами, в памяти компьютера под каждый символ отводится ровно 1 байт, при этом код символа помещается в младшие биты, а старший бит не используется.
Главный недостаток стандарта АSCII заключается в том, что он рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения АSCII -кодировки, в которых применялись однобайтовые коды символов; при этом первые 128 символов кодовой таблицы совпадали с кодировкой АSCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано по нескольку вариантов кодовых таблиц (например, для русского языка их около десятка!).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Указан кодовую таблицу, автоматически выбирают и язык, которым можно пользоваться в дополнение к английскому; точнее, выбирается то, как будут интерпретироваться символы с кодами более 127.
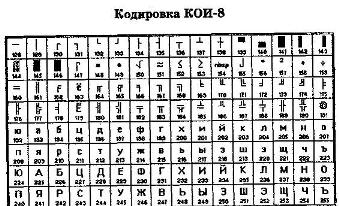
Для русского языка наиболее распространенными являются однобайтовые кодовые таблицы СР-866, Windows-1251 и КОИ-8. В них первые 128 символов совпадают с АSCII -кодировкой, а русские буквы размещены во второй части таблицы, однако коды русских букв в этих кодировках различны!
Lля устранения этого ограничения в 1993 году был разработан новый стандарт кодирования символов, получивший название Unicode, который, по замыслу его разработчиков, позволил бы использовать в текстах любые символы любых языков мира.
В Unicode на кодирование символов отводится 31 бит. Первые 128 символов (коды 0—127) совпадают с таблицей АSCII; далее размещены основные алфавиты современных языков: они полностью умещаются в первой части таблицы, их коды не превосходят 65 536 = 216
Стандарт Unicode описывает алфавиты всех известных, в том числе и «мертвых», языков; для языков, имеющих несколько алфавитов или вариантов написания (например, японский и индийский), закодированы все варианты; в кодировку Unicode внесены все математические и иные научные символьные обозначения и даже некоторые придуманные языки (например, письменности эльфов и Мордора из эпических произведений дж. Р. Р. Толкиена). Потенциальная информационная емкость 31-битового Unicode столь велика, что сейчас используется менее одной тысячной части возможных кодов символов!
В современных компьютерах и операционных системах используется укороченная, 16-битовая версия Unicode, в которую входят все современные алфавиты.
Кодирование
текстовой информации.
Для представления текстовой информации используются 256 различных
символов (строчные и прописные буквы русского и латинского алфавитов,
знаки препинания, цифры и т.д.). Если считать, что использование каждого
символа равновероятно, то его информационный вес: ![]() бит
бит ![]() байт.
Для двоичного кодирования 1 символа требуется 1 байт (8 битов). Тексты
хранятся в памяти компьютера в двоичном коде и программным способом
преобразуются в изображение на экране. В текстовом режиме экран разбит
на 25 строк по 80 символов в строке.
байт.
Для двоичного кодирования 1 символа требуется 1 байт (8 битов). Тексты
хранятся в памяти компьютера в двоичном коде и программным способом
преобразуются в изображение на экране. В текстовом режиме экран разбит
на 25 строк по 80 символов в строке.
Информационный объем текстового сообщения в байтах численно равен
количеству символов ![]() В
битах объем текстового файла равен:
В
битах объем текстового файла равен: ![]()
Система распознавания текста
При работе с первоисточниками (или, как принято говорить при описании офисных технологий, с исходными документами) наиболее оптимальным может оказаться ввод какой-либо первичной текстовой информации без помощи клавиатуры. Такой способ может быть реализован получением данных из глобальных или локальных компьютерных сетей, посредством распознавания речи или оптического распознавания текста. В данной статье пойдет речь о последнем из названных способов.
Имея текст, напечатанный в типографии, на пишущей машинке, на принтере, копировальном аппарате, в факс-машине, то есть буквально текст любого происхождения, теперь - даже написанным от руки, Вы можете без помощи клавиатуры получить его в электронном виде для последующего редактирования, перевода или хранения на компьютере. Для этого Вам потребуются сканер и программа, называемая системой оптического распознавания - OCR. Каждый такой программный продукт имеет простейший автоматический режим "сканируй и распознавай", реализованный с помощью одной кнопки. Однако для того, чтобы достигнуть лучших из возможных для данной системы результатов, желательно (а нередко и обязательно) предварительно заниматься "ручной" настройкой системы распознавания на конкретный вид текста, а точнее на способ и качество начертаний букв и других знаков. Чтобы проделывать такие настройки, в меню программ обязательно отражены соответствующие регуляторы, но пользоваться ими удобнее при некотором знакомстве с принципами оптического распознавания. На их описании мы, главным образом и остановимся, поскольку даже в компьютерных журналах, которые регулярно печатают материалы о конкретных системах распознавания, практически не находится статей, выходящих за рамки покупательского гида, и сама технология остается за рамками повествования.
Делая "первый шаг", OCR должен разбить страницу на
блоки текста, основанного на особенностях правого и левого выравнивания
и наличия нескольких колонок. Потом эти блоки разбиваются в
индивидуальные метки чернил (типографской краски и т.п.), которые, как
правило, соответствуют отдельным буквам. Алгоритм распознавания делает
предположения относительно соответствия чернильных меток символам; а
затем делается выбор каждой буквы и цифры. В результате страница
восстанавливается в символах текста (причем, в соответствующем оригиналу
формате).
OCR-системы могут достигать наилучшей точности распознавания свыше 99
процентов для качественных изображений, составленных из обычных шрифтов.
Хотя это число кажется почти совершенным, уровень ошибок все же
удручает, потому что, если имеется приблизительно 1500 символов на
странице, то даже при коэффициенте успешного распознавания 99,9%
получается одна или две ошибки на страницу, требуя человеческого
контроля результатов для гарантирования правильности соответствия
оригиналу. Встречающиеся в жизни тексты порой весьма далеки от
совершенных, и процент точности распознавания для "плохих" текстов часто
недопустим для большинства приложений. Грязные изображения - здесь
наиболее очевидная проблема, потому что даже малые пятна могут затенять
определяющие части символа или преобразовывать один в другой.
Если документ был ксерокопирован, нередко возникают разрывы и слияния
символов (такие тексты нередко возникают и при сканировании). Любой из
этих эффектов может заставлять ошибаться, потому что некоторые из OCR
систем полагают, что каждая соединенная черная метка должна быть
одиночным символом.
Страница, расположенная с нарушением границ или перекосом, создает
немного искаженные символьные изображения, которые могут путать
программное обеспечение распознавания. Даже, когда изображения - чистые,
странные или декоративные начертания могут вызывать проблемы, потому что
они растягивают символы в различные формы для художественного эффекта.
Кроме того буквы могут иметь вариации среди начертаний того же самого
наименования шрифта, когда, к примеру, символы, воспроизведенные
принтером HP DeskJet, отличны от символов, которые напечатаны на Apple
LaserWriter.
Люди способны быстро различить на бумаге "h" и "b" еще и потому, что они знают контекст слова, в котором встречаются эти буквы. По этой причине программное обеспечение системы OCR включает словари для помощи алгоритмам распознавания. Словари предоставляют справки во многих случаях, но быстро отказывают, когда, скажем, программное обеспечение сталкивается с именами собственными, которые не находятся в словаре.
Настольные издательские системы
Применяются для профессиональной издательской деятельности. Позволяют осуществлять электронную верстку широкого спектра основных типов документов типа информационного бюллетеня, цветной брошюры, каталога, справочника. Позволяют решать задачи:
1. компоновать (верстать) текст;
2. использовать всевозможные шрифты и выполнять полиграфические изображения;
3. осуществлять редактирование текста на уровне лучших текстовых процессоров;
4. обрабатывать графические изображения;
5. выводить документы полиграфического качества;
6. работать в сетях на разных платформах.
Примерами таких пакетов являются: Corel Ventura, Page Maker, QuarkXPress, Frame Maker, MS Publisher, Page Plus, Compu Work Publisher.